This article is a spinoff of Local image generation on Mac: 10 models compared, my top pick flipped. Per-model deep dive, v1.
TL;DR
- Stable Diffusion 1.5 was released in 2022 and is the ancestor of local image generation as we know it
- On Mac M1 Max 64GB / Apple MPS, ~13 sec per image (20 step / 512px), 7 sec to load
- By 2026 standards: picture-book illustration quality, can't even spell English text
- Still useful as an absolute baseline. The "wow, that's good" feeling you get from Flux dev / Qwen Lightning is calibrated by what SD 1.5 produces
- License is CreativeML OpenRAIL-M (the standard at release), commercial use allowed but not recommended at modern quality bars
- Verdict: historical reference / fallback for ultra-low-resource environments only
Why include this model
To make "the starting point of local image generation" part of the comparison, so the 4-year evolution is visible. When this series says "Flux dev tops photorealism" or "Qwen Lightning is the best local option," you need an absolute reference to know good compared to what. SD 1.5 is that reference.
What I expected:
- Material for laughable failures: ramen with 5 eggs on it, hallucinated English text that reads like a foreign language, an izakaya prompt that came back as a Buddhist scripture scroll, etc.
- A baseline for "how far have we come in 4 years"
- Crushing lightness — 4GB barely affects anything else running on the Mac
What I didn't expect:
- Anything usable as modern blog illustration
- Legible text rendering
- Coherent object placement
Result: it satisfies the "historical reference" role, but never enters the candidate list for actual modern illustrations. After looking at Lightning / Flux dev / Gemini, SD 1.5 reads as "the thing that made today possible."
Environment setup
pip install diffusers==0.37.1 torch==2.11.0 transformers
Load code:
from diffusers import StableDiffusionPipeline
import torch
pipe = StableDiffusionPipeline.from_pretrained(
"stable-diffusion-v1-5/stable-diffusion-v1-5",
torch_dtype=torch.float16,
).to("mps")
image = pipe(
prompt="...",
num_inference_steps=20,
guidance_scale=7.5,
height=512,
width=512,
).images[0]
Hardware requirements:
| Item | Value |
|---|---|
| Mac | M1 Max / 64GB (works on 16GB realistically) |
| Model | 4GB (fp16) |
| Resolution | 512x512 (1024 wasn't trained, breaks down) |
| Per image | ~13 sec (20 step / 512px / MPS) |
| Load time | ~7 sec |
By far the lightest among local image-gen models. Running it in the background while doing other Mac work has negligible impact on the rest of the system.
All 8 prompts
| # | Prompt | Image | Time |
|---|---|---|---|
| 01 | a cute cat sitting on a wooden bench in a sunny park |  |
13.5s |
| 02 | a bowl of ramen with chashu and soft-boiled egg |  |
13.0s |
| 03 | a wooden sign with "LOCAL AI" |  |
13.0s |
| 04 | a developer's t-shirt with "M1 MAX 64GB" retro 80s style |  |
12.9s |
| 05 | a woman developer working at a laptop |  |
13.0s |
| 06 | a glowing AI brain made of circuits and neon |  |
12.9s |
| 07 | three robots playing chess in a sunlit library |  |
12.9s |
| 08 | a wooden izakaya sign with the kanji "居酒屋" |  |
12.9s |
Total for 8 images: ~104 seconds = 1m40s. Compared to Qwen Full's 12 hours, that's roughly 430× faster — but quality is in a completely different league.
Per-prompt evaluation
01 Cat — vertically stretched face, eyes misaligned
Cat on a bench. The face is stretched vertically and the eyes are off-center. Classic "Stable Diffusion can't quite do animal faces" symptom. Background is surprisingly natural (wood grain on the bench, greenery, depth of field).
| Flux dev (2024) | Qwen Lightning (2025) | SD 1.5 (2022) |
|---|---|---|
 |
 |
|
| Drifts to anime / illustration style | Mostly photorealistic, slight illustration feel | Stretched face, misaligned eyes, picture-book illustration |
02 Ramen — five eggs
Five eggs on a single bowl. The prompt clearly said "soft-boiled egg" — singular — and SD 1.5 disagreed four times. Textbook example of "the model has an opinion about quantity, and it's not yours." (For context: Japanese ramen normally has one egg, halved. Five would be a culinary war crime.)
| Flux dev (2024) | Qwen Lightning (2025) | SD 1.5 (2022) |
|---|---|---|
 |
 |
|
| Has cilantro (Southeast Asian crossover) | Just the mystery green vegetable, otherwise near-perfect | Five eggs on one bowl |
→ In 4 years, ramen actually became ramen. The "wow, this looks good" reaction to Flux dev / Qwen Lightning is anchored by what SD 1.5 produces.
03 LOCAL AI — OOLDD AIXNIA, an invented language
Can't even spell Latin characters correctly. What comes out is OOLDD AIXNIA or something close to it — corrupted strings. SD 1.5 treats text as "shape" and has no ability to spell meaningful strings.
| SDXL base (2023) | Flux dev (2024) | SD 1.5 (2022) |
|---|---|---|
 |
 |
|
| Degrades to "LOCAL LL" | "LOCAL AI" perfect | OOLDD AIXNIA mystery language |
→ You can see at a glance how text encoder generation rollovers enabled actual spelling. CLIP-L (77 tokens) → T5-XXL (thousands of tokens) progressively improved English text rendering. SD 1.5 sits at the starting point, where even spelling Latin characters doesn't work.
04 M1 MAX 64GB t-shirt — same illegibility
The 80s t-shirt vibe is there, but the text is mostly illegible. It gets processed as decorative graphics rather than letters.
| Flux dev (2024) | SD 1.5 (2022) |
|---|---|
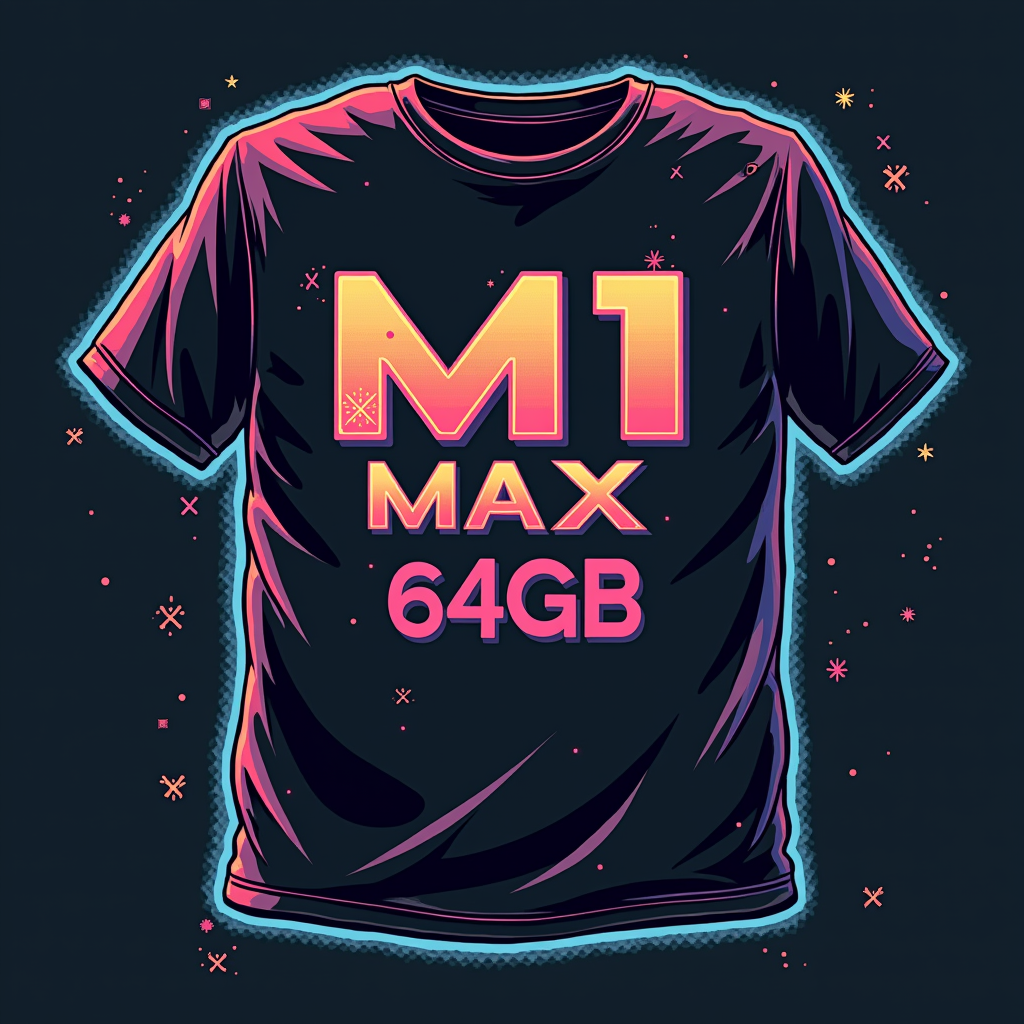 |
|
| "M1 MAX 64GB" perfect + 80s synthwave fully captured | Text is symbolized, illegible |
05 Woman developer — surprisingly passable
Woman, glasses, laptop, in front of a window. No finger-disappearance issue — hands are hidden under the desk, which is a slightly cheaty form of stability compared to SDXL. The white mug and laptop bag in the background look natural.
| Flux dev (2024) | Qwen Lightning (2025) | SD 1.5 (2022) |
|---|---|---|
 |
 |
|
| Photorealistic, plants and notebook props included | Photorealistic, natural as stock photo | Looks fine at first glance (hides hands to dodge) |
→ For simple compositions, SD 1.5 can pass at a glance. Same "stability through omission" tendency as SDXL Turbo. But modern models have moved on to "actually draw the hands without breaking them" — SD 1.5's hide-to-survive is dated.
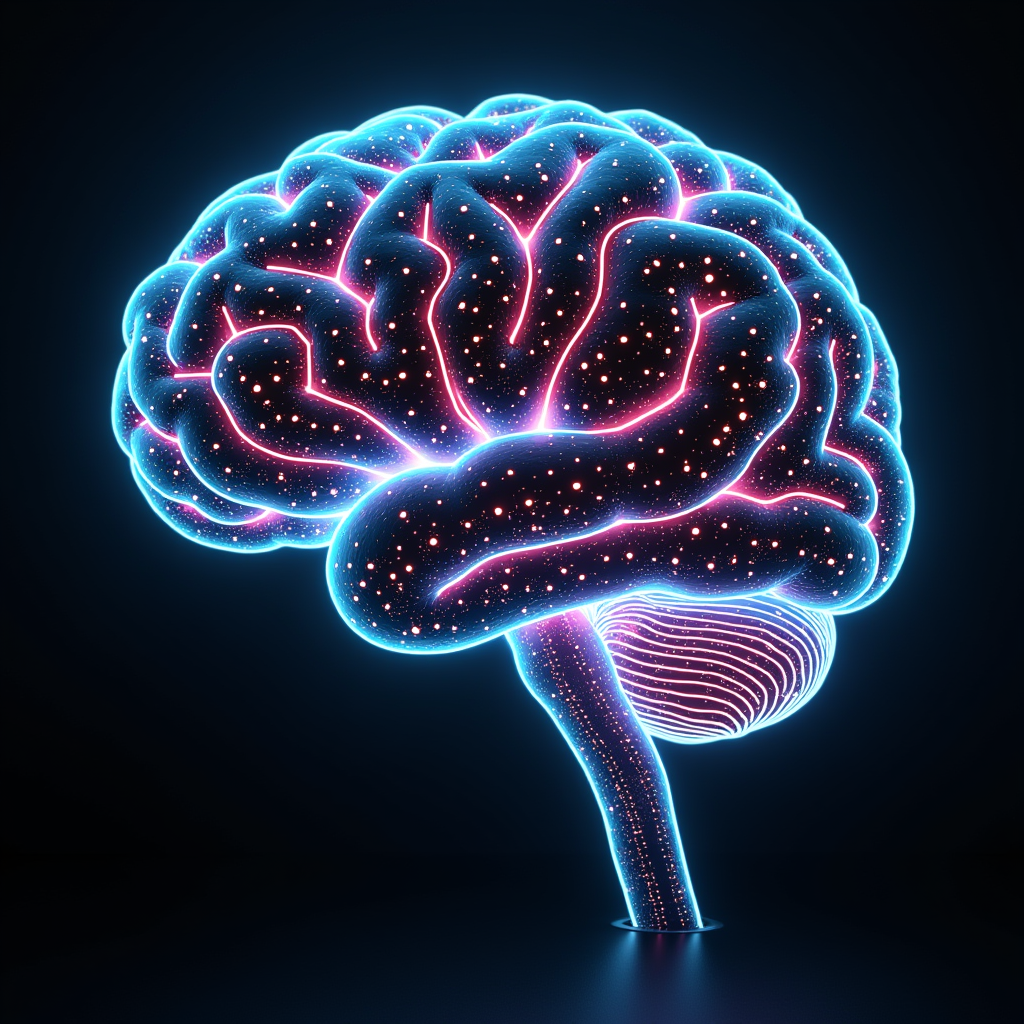
06 AI brain — neon circuit, NES vibes
Green neon circuits with a brain silhouette. NES-era retro digital feel. It has a vibe, but is nowhere near the resolution of Flux dev / Qwen Lightning. Cute as naive style, unusable as modern illustration.
| Flux dev (2024) | Qwen Lightning (2025) | SD 1.5 (2022) |
|---|---|---|
 |
 |
|
| Neon particles, light streaks, top of local | Practical, improved over Full | NES-era retro digital |
→ For abstract art, SD 1.5's naivety can ironically read as flavor, but at modern illustration standards it loses on detail and resolution. For cyberpunk-style work, go to Flux dev.
07 Robots and chess — forgets the robots
Prompt was "three robots playing chess." What came out: two children playing chess. Textbook example of SD 1.5's incomplete prompt parsing.
- "three robots" → quantity ignored + robots forgotten
- "in a sunlit library" → library rendered (bookshelves in background)
- "warm afternoon light" → warm lighting present
Each element gets reflected to a different degree. Plurals and abstract nouns like "robots" tend to get ignored. This is the limit of SD 1.5's text encoder (CLIP ViT-L/14).
| SDXL base (2023) | Flux dev (2024) | SD 1.5 (2022) |
|---|---|---|
 |
 |
|
| Three robots, drawn correctly | Three robots, rich expression and hand detail | Forgets the robots, draws two children |
→ Response to "three robots" improves dramatically across SD 1.5 → SDXL generations: SD 1.5 (forgotten) → SDXL base (3 robots OK) → Flux family (3 + facial detail). Effect of strengthening the text encoder (CLIP-L alone → CLIP-L+G → T5-XXL).
08 Izakaya — comes back as a Buddhist scripture scroll
I expected an izakaya (Japanese pub) sign. What I got: a hanging scroll of Buddhist scripture. No building, no paper lantern, no warm light — just a calligraphy work like you'd see at a temple gift shop.
The structure: SD 1.5 tries to retrieve "居酒屋" (kanji for izakaya) from the training data, hits the wrong association — kanji → calligraphy → scroll → temple — and lands on something completely different. Imagine asking for "a pub sign" and getting "a parchment of medieval prayer text" — that level of category miss.
| Flux dev (2024) | Qwen Lightning (2025) | SD 1.5 (2022) |
|---|---|---|
 |
 |
|
| Kyoto townhouse style + made-up kanji "典桔" | "居酒屋" 3 chars perfect + warm-light storefront | Buddhist scripture scroll (no building at all) |
→ SD 1.5's handling of Asian elements is catastrophic. Flux dev produces fake kanji, Qwen Full hedges, but SD 1.5 doesn't even reach the category "izakaya." Until Qwen Lightning shipped, there was no local option that could write kanji — that 4-year history shows in this single comparison.
What worked
- Ultra-light: 4GB, 7-sec load, coexists with everything else on the Mac
- Stable as a classic: 4 years of operational track record, troubleshooting info is overwhelming
- CreativeML OpenRAIL-M license: commercial OK (though I wouldn't recommend it on quality)
- Rich ecosystem: massive number of LoRAs, ControlNet variants, inpainting tools
- Value as an "absolute baseline": when used as a comparison, the awesomeness of modern models becomes legible
What didn't
- Picture-book illustration quality: not usable at modern illustration standards
- Text rendering NG: can't even spell "LOCAL AI"
- Asian elements catastrophic: kanji prompt collapses into a temple scroll
- Incomplete prompt parsing: ignores quantity specifications and plurals
- Locked to 512 resolution: 1024 has no training data, breaks
Where this model still earns its keep
Honestly: SD 1.5's quality is below what 2026 calls "practical."
- 02 ramen has 5 eggs on it
- 03 LOCAL AI becomes
OOLDD AIXNIA, an invented language - 07 "three robots" silently turn into "two children"
- 08 izakaya comes out as a Buddhist scripture scroll (wrong religion, wrong building, wrong everything)
- Locked to 512 resolution, no 1024 training data
These never happen with Flux schnell / Qwen Lightning, so there is no scenario where SD 1.5 is your modern illustration candidate. If you need reasons to still use it:
- ✅ Historical reference: showcase "the starting point of local image generation," visualize 4 years of progress
- ✅ Absolute baseline: the floor when evaluating other models. The "wow" of Flux dev / Qwen Lightning is calibrated by what SD 1.5 puts out
- ✅ Ecosystem experiments: the volume of LoRA / ControlNet / inpainting tooling is largest for SD 1.5; if you need niche use cases, still useful
- ✅ Ultra-low-resource environments: floor of local image generation, runs on 4GB / 4GB VRAM
- ❌ Modern illustration candidate: 2022-level quality, looks picture-book by today's standards
- ❌ Part of this article's adoption plan: never lands on the (English-circle = Flux dev / Asian = Qwen Lightning) plan
Gotchas / tips
1. Don't run it at 1024x1024
# ❌ It breaks if you go SDXL-style
image = pipe(prompt=p, height=1024, width=1024, ...)
# ✅ SD 1.5 was trained on 512
image = pipe(prompt=p, height=512, width=512, ...)
SD 1.5's training data is 512x512-centric. 1024 is out of distribution — repeating patterns or composition collapse. There's no point running SD 1.5 at 1024 (use SDXL for that).
2. Keep prompts simple, use negative prompts
SD 1.5 is a model designed around negative prompts. Flux family stopped using them, but for SD 1.5:
neg = "low quality, blurry, distorted, extra fingers, bad anatomy, worst quality"
image = pipe(prompt=p, negative_prompt=neg, ...).images[0]
This mitigates finger problems and face distortion somewhat. Flux-era models bake equivalent processing into the model, so it's unnecessary there, but SD 1.5 needs it explicit.
3. Try multiple seeds — it's a lottery
SD 1.5 has high generation variance. Rolling 5–10 different seeds on the same prompt usually gives you one decent shot. Flux dev / Qwen Lightning hit near-max quality on the first seed; SD 1.5 expects you to play the lottery.
4. Understand LoRA / ControlNet
Bare SD 1.5 breaks, but specialize it via LoRA + lock composition with ControlNet and you can still get usable material in 2026. A "naked SD 1.5" review like this one is the floor sans ecosystem.
5. Be aware of CLIP text encoder limits
SD 1.5's text encoder is CLIP ViT-L/14 with a 77-token limit. Long prompts get truncated from the back. Put important keywords first. Flux family's T5-XXL (thousands of tokens) is orders of magnitude more expressive.
Witnessing 4 years of progress
Lined up in chronological order across this article series:
| Year | Model | Size | Resolution | Character |
|---|---|---|---|---|
| 2022 | SD 1.5 | 4GB | 512 | Picture-book level, text NG, Asian elements broken |
| 2023 | SDXL base (2023) | 7GB | 1024 | Mid-tier stable, element-addition habit, classic SDXL |
| 2023 | SDXL Turbo (2023) | 7GB | 512 | ADD distillation, 1-sec gen, blurry |
| 2024 | SD 3.5 Medium (2024) | 5GB | 1024 | DiT, thumbnail OK, full-size NG |
| 2024 | Flux schnell (2024) | 23GB | 1024 | 4-step Apache 2.0 |
| 2024 | Flux dev (2024) | 23GB | 1024 | Top photorealism, English text perfect, Asian NG |
| 2025 | Qwen-Image (Full) | 40GB | 1024 | Kanji OK, 93 min/image |
| 2025 | Qwen-Image Lightning | 40GB | 1024 | 8-step LoRA, top local candidate |
→ In 4 years: 10× the size, 4× resolution, text rendering went from broken to perfect, Asian elements went from broken to perfect. Watching SD 1.5 lets you feel just how big that delta is.
Comparison article and next models
Related articles in this series:
- v2 SDXL base 1.0 — Mid-tier stability with a habit of adding elements you didn't ask for (direct successor)
- v3 SDXL Turbo — The cost of Adversarial Diffusion Distillation (a sibling distilled at the same size)
- v8 Qwen-Image Lightning — Distilled to 8 steps, then it became the best local model (where we landed 4 years later)
Test environment: Mac M1 Max 64GB / macOS 25.4 / Python 3.14 / Diffusers 0.37.1 / PyTorch 2.11 (MPS) Run log: 2026-04-29, Stable Diffusion 1.5 (stable-diffusion-v1-5/stable-diffusion-v1-5, 20-step / guidance 7.5 / 512px)
